Sanitizing User Input

























Sanitizing User Input
- Example Web App
- Bad User Input
- Sanitizing User Input
- Disallowing Content
- Escaping Content
- Cleaning Content
- Stripping Content
- Replacing Content
- Client Side Editing
- Attributes and URLs
- Summary
- Homework
Never trust anything that comes from the client. - ancient proverb
Now we know how to get user input using HTML forms and POST requests that trigger the doPost() function of our servlet classes.
But we have to be very careful when showing that user input, especially to other users. We can’t just allow arbitrary content, because then malicious users could do bad stuff like inject HTML or JavaScript into our page, which would allow them to redirect browsers, steal information, or exploit cross-site scripting on your site.
Instead, we have to sanitize the data that we get from our users, so that it only contains safe content. There isn’t a single best way to do this though! It’s more like a series of questions that you have to answer, and the answers depend on exactly how you want your site to act and what kinds of content you want to allow.
Example Web App
Let’s start with an example web app that takes input from a user and then displays it. Here’s our servlet class:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.content = request.getParameter("content");
//redirect to a GET request
response.sendRedirect(request.getRequestURI());
}
}
In its doGet() function, this servlet adds the content to the request, and forwards it to a JSP file for rendering. The doPost() function gets the submitted content parameter, stores it, and then redirects back to a GET request.
The JSP file looks like this:
<!DOCTYPE html>
<html>
<head>
<title>User Input Example</title>
</head>
<body>
<p>Content:</p>
<hr/>
<p>${content}</p>
<hr/>
<form action="" method="POST">
<textarea name="content"></textarea>
<br/>
<input type="submit" value="Submit">
</form>
</body>
</html>
This file just shows the content, and then a form that allows the user to change the content.
Finally, here’s the web.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
<servlet>
<servlet-name>MyServlet</servlet-name>
<servlet-class>MyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>MyServlet</servlet-name>
<url-pattern>/home</url-pattern>
</servlet-mapping>
</web-app>
The web.xml file maps the /home URL to our servlet. Run this servlet and visit http://localhost:8080/home, and you should see this:
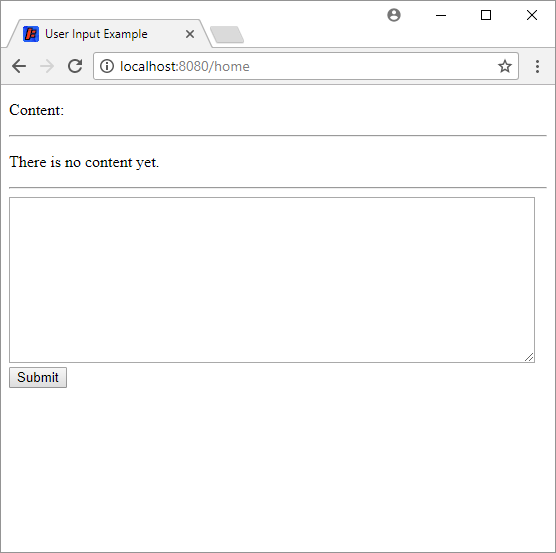
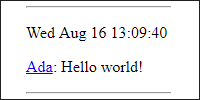
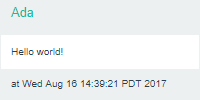
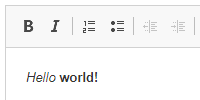
You can enter some text to make sure it works.
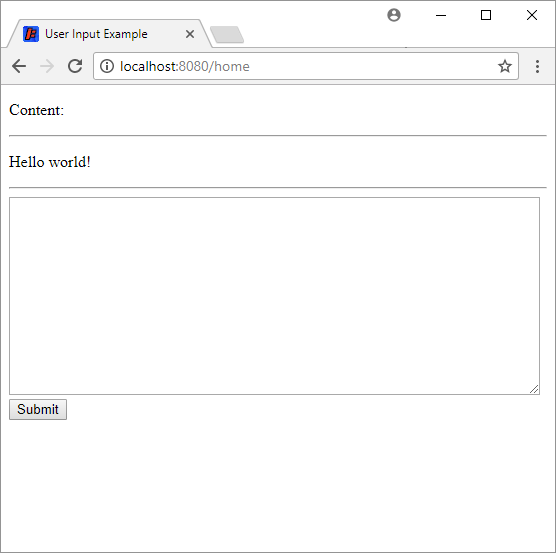
Here I’ve typed Hello world! and clicked the Submit button. The servlet stored that content, and now the JSP page displays it. You can think of this as a very simple version of a website that allows you to submit posts, like Twitter or Facebook or whatever.
Bad User Input
But what happens if you enter html?
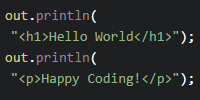
Try entering something like <h1>oh no</h1> into the text input and clicking the Submit button. You’ll see that the html is rendered in the page:
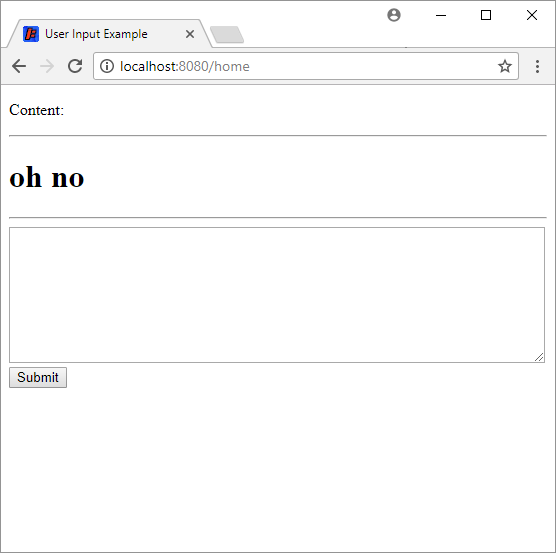
This is because our JSP is just outputting the content directly into the HTML on this line:
<p>${content}</p>
So if content is <h1>oh no</h1>, then the HTML that gets rendered to the screen is <p><h1>oh no</h1></p>.
Allowing users to input arbitrary HTML can cause problems on your site. Imagine a site like Twitter or Facebook or Tumblr, where one user’s posts are shown to other users. If I’m a malicious user, I could:
- Mess up the formatting of your site.
- Redirect your user’s browsers to my own site.
- Steal your user’s data.
- Exploit cross site scripting.
As another example, try entering this as the content:
<script>
alert("Pay me a million dollars or I'll delete your files!");
</script>
This content is just a <script> tag that contains JavaScript code, which shows a popup box to scare the user. If you submit this content, you’ll see that a popup box is displayed whenever you load the page. Now imagine if a user got this kind of content onto your homepage, or added a link to a scam site, or inserted a fake login form that then submitted the username and password to their own server.
Hopefully this shows you why you shouldn’t just display user input. What can we do about it?
Sanitizing User Input
Now we know that we shouldn’t just allow the user to enter arbitrary content. So we face a decision: what should we do with user-entered HTML content? We basically have five options:
-
Disallow content so you show an error if the user tries to submit bad content.
-
Escape content so HTML is rendered as text.
<p>Hello <script>badStuff()</script> world!</p>becomes<p>Hello <script>badStuff()</script> world!</p>. Remember that<and>are displayed as<and>instead of being parsed as HTML tags. -
Clean content to allow only safe HTML through.
<p>Hello <script>badStuff()</script> world!</p>becomes<p>Hello world!</p>. -
Strip content to not allow any HTML at all.
<p>Hello <script>badStuff()</script> world!</p>becomesHello world!. -
Replace content so users can enter non-HTML tags that you convert to HTML.
some [b]bold[/b] contentbecomes<p>some <span class="bold">bold</span> content</p>, for example. Note that you’d still have to decide what to do with normal HTML mixed with this type of content.
Which approach you choose depends on how you want your web app to work, your security concerns, and honestly how much time you feel like investing in this part of your site. (Do you do the easy thing that takes 5 minutes, or do you spend a ton of time perfecting your input flow?) You’ll actually probably use a combination of several of the above options.
Disallowing Content
Disallowing content is probably the easiest option, but even then you have more questions to answer:
- Do you want to use a whitelist that makes sure the input only contains allowed content?
- Or do you want to use a blacklist that checks for disallowed content?
Using a whitelist is safer, but more restrictive. You’ll typically use a regular expression to disallow content, whether you use a whitelist or a blacklist.
Let’s modify our servlet class to use a whitelist that only allows users to enter letters, numbers, and spaces.
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
if(!request.getParameter("content").matches("[\\w*\\s*]*")){
request.setAttribute("error", "Please enter only letters, numbers, and spaces.");
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
return;
}
this.content = request.getParameter("content");
response.sendRedirect(request.getRequestURI());
}
}
Now the doPost() function uses a regular expression along with the matches() function to make sure the input value contains only letters, numbers, and spaces. If it does not match our regular expression, that means the input contains illegal characters, and the servlet adds an error attribute and forwards the request to the JSP. If the input does match the regular expression, that means it only contains letters, numbers, and spaces, and we allow the request through.
Now the JSP just displays the error if it’s present:
<!DOCTYPE html>
<html>
<head>
<title>User Input Example</title>
</head>
<body>
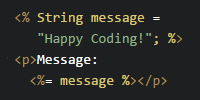
<% if(request.getAttribute("error") != null){ %>
<h2 style="color:red">${error}</h2>
<% } %>
<p>Content:</p>
<hr/>
<p>${content}</p>
<hr/>
<form action="" method="POST">
<textarea name="content"></textarea>
<br/>
<input type="submit" value="Submit">
</form>
</body>
</html>
Now try entering stuff like this contains <div>html</div> tags to see that this input generates an error. The regular expression in this example is overly simplified, so it also disallows punctuation and non-ascii letters. That may or may not be what you want, so check out the Pattern class for more info on regular expressions.
This approach of disallowing certain content is pretty common for usernames, especially because you’ll probably use them in URLs, which have their own content requirements. So you probably don’t want a username to be /index.html or a bunch of spaces or HTML content.
Escaping Content
HTML tags are delimited by the < and > symbols, as in <p>hello world</p>. If your browser sees one of these symbols, it knows that the content is an HTML tag, so should be used to format the text instead of displaying to the viewer.
But what if we want our text to include a < or > symbol? What if we want to display something like I really love the <hr/> tag! without the <hr/> part being parsed as HTML?
We need to escape these characters using HTML entities. HTML entities are a special string of characters that are rendered as a single character, and are not parsed as HTML tags.
<renders as<>renders as>&renders as&"renders as"'renders as'
The < and > entities are good for rendering content as pure text instead of HTML that should be parsed. The & entity is needed because a normal & ampersand is treated as the beginning of an entity (so if you wanted your text to render as < instead of <, you’d have to use &lt;). The " and ' entities are useful when you want to put user content inside element attributes (for example, if you wanted to do <div id="${username}">, what would happen if username contained a " symbol?).
So, if we want to just render the user’s content exactly as they entered it, without it being parsed as HTML, then we just need to replace any symbols that might be parsed as HTML or interfere with our formatting with their corresponding HTML entity. We could probably do this using the replace() and replaceAll() functions, but instead of reinventing the wheel, let’s use a libary that does this for us.
The Apache Commons Lang library provides several functions that are useful for escaping content. Download the libary .jar file and copy it to the lib folder in your web app directory. Now we can use that library in our servlet:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.lang3.StringEscapeUtils;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.content = StringEscapeUtils.escapeHtml4(request.getParameter("content"));
response.sendRedirect(request.getRequestURI());
}
}
Now the doPost() function uses the escapeHtml4() function to escape the content, which renders it as pure text instead of HTML content:
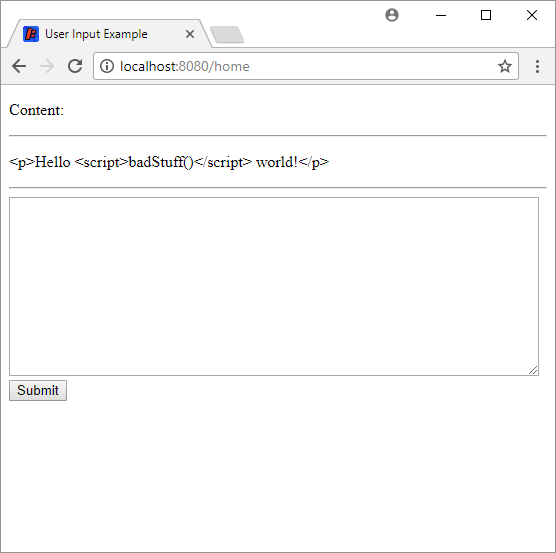
This approach of escaping content is useful if you want a very basic text editor that does not offer any styling, and you want to render text exactly how the users entered it.
Cleaning Content
Not all HTML tags or attributes are dangerous, so it might make sense for you to allow some HTML, as long as you don’t allow the dangerous stuff. For example you might want to allow <p> and <ul> tags, but not <script> or <iframe> tags.
The jSoup library provides functionality for cleaning HTML and only allowing certain tags in content. Download the .jar file and copy it into the lib folder of your web app directory, so we can use it in our servlet class.
To use jSoup, first think about which tags you want to allow, and then find a whitelist that matches what you want. Then just pass that whitelist into the Jsoup.clean() function along with the content you want to clean.
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.jsoup.Jsoup;
import org.jsoup.safety.Whitelist;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.content = Jsoup.clean(request.getParameter("content"), Whitelist.basic());
response.sendRedirect(request.getRequestURI());
}
}
Now the doPost() function uses the Jsoup.clean() function to only allow tags in the basic whitelist. That means we can enter tags like <p> and <ul>, but not tags like <script> or <img>. Try entering different types of content, and trying out different whitelists.
You can read more about jSoup here.
This option is useful if you want to allow the user to enter HTML to format their text, or if you want to use a rich text editor on the client side, which we’ll see in a minute.
Stripping Content
We could also be more strict and just not allow any HTML tags through. This is basically just a stricter version of the cleaning option we just saw, so we can use jSoup to do this as well:
this.content = Jsoup.clean(request.getParameter("content"), Whitelist.none());
The Whitelist.none() whitelist tells jSoup to not allow any HTML tags at all, so they’re all stripped from the content. Try entering different types of content to see what happens with it.
This option is useful if you just want to ignore HTML tags completely.
Replacing Content
Another option is to avoid HTML altogether and use a different markup language in your editor, which you then convert to HTML. For example, let’s say we want to allow users to add bolding to their content using tags that we make up: (bold) and (/bold). A user might enter something like this:
Here is some (bold)bolded(/bold) text!
Which we want to convert to:
Here is some <strong>bolded</strong> text!
For this simple example, we can use the replace() function:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.lang3.StringEscapeUtils;
import org.jsoup.Jsoup;
import org.jsoup.safety.Whitelist;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String enteredContent = request.getParameter("content");
// make sure user didn't enter HTML along with our markup
String escapedContent = StringEscapeUtils.escapeHtml4(enteredContent);
// replace our markup with HTML
String parsedContent = escapedContent.replace("(bold)", "<strong>").replace("(/bold)", "</strong>");
//make sure generated HTML is valid and all tags are closed
String cleanedContent = Jsoup.clean(parsedContent, Whitelist.none().addTags("strong"));
this.content = cleanedContent;
response.sendRedirect(request.getRequestURI());
}
}
Now the doPost() function processes the input by first escaping it to prevent any HTML, then uses the replace() function to convert our (bold) markup to the <strong> HTML tag, then uses jSoup to make sure the tags are closed and the HTML is formatted properly. Note that there are other ways to handle this: for example, maybe you’d also want to allow the user to enter <strong> HTML as well. It depends on how you want your site to work.
The replace() function will work for very simple content, but for anything more complex you’re probably going to want to find a library that does the replacement for you. There are a bunch of lightweight markup languages designed for this purpose, such as BBCode and Markdown. Googling stuff like “Java bbcode library” will return libraries that you can use to do the replacement for you.
This approach of replacing content allows users to enter formatting without knowing HTML, and helps you guarantee that only safe content is allowed.
Client Side Editing
We’ve covered the processing that needs to be done on the server side, but all of our examples have used a very basic text area to allow users to enter text. You can spruce this up using JavaScript to do stuff like:
- Check for disallowed content and show a warning before the user clicks submit.
- Show a preview of what a user’s post will look while they’re typing it.
- Use a rich text editor to give the user a WYSIWYG (what you see is what you get) input.
The general approach is to use JavaScript to setup a listener that detects when the user types something, and then taking that content and checking it for disallowed content or passing it through a parser to generate a preview. For simple stuff you can probably do this yourself, but as per usual, for more complicated content or functionality, you should probably just use a library.
Googling “javascript rich text editor” or “javascript editor preview library” will return a bunch of results, and I’d suggest trying out a few to see which one you like best for your users.
For example, let’s use the CKEditor JavaScript library to show a rich text editor instead of a boring text area. We can consult the CKEditor documentation to figure out exactly how to use the library. Our JSP is now:
<!DOCTYPE html>
<html>
<head>
<title>User Input Example</title>
<script src="http://cdn.ckeditor.com/4.7.2/basic/ckeditor.js"></script>
</head>
<body>
<p>Content:</p>
<hr/>
<p>${content}</p>
<hr/>
<form action="" method="POST">
<textarea name="content"></textarea>
<br/>
<input type="submit" value="Submit">
</form>
<script>
CKEDITOR.replace('content');
</script>
</body>
</html>
Now we load the CKEditor library, and then call the CKEDITOR.replace() function to replace the basic text area with a rich text area.
Note that we still need to do server-side processing of the content, even if we’re using a rich text editor. This is to prevent malicious users from doing stuff like:
- Disabling JavaScript and visiting your site to disable client-side processing.
- Editing your site using the developer tools to disable your client-side processing.
- Creating their own basic HTML form that posts to your server.
- Using a program like cURL to post content directly to your server.
The point is, you should never trust any content that comes from the client side. Always perform server-side checks!
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.jsoup.Jsoup;
import org.jsoup.safety.Whitelist;
public class MyServlet extends HttpServlet {
private String content = "There is no content yet.";
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setAttribute("content", content);
request.getRequestDispatcher("WEB-INF/jsp/render.jsp").forward(request,response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.content = Jsoup.clean(request.getParameter("content"), Whitelist.basic());
response.sendRedirect(request.getRequestURI());
}
}
The doPost() uses jSoup’s basic whitelist to make sure only valid HTML is allowed.
Now if we run our server, we’ll see the rich text editor:
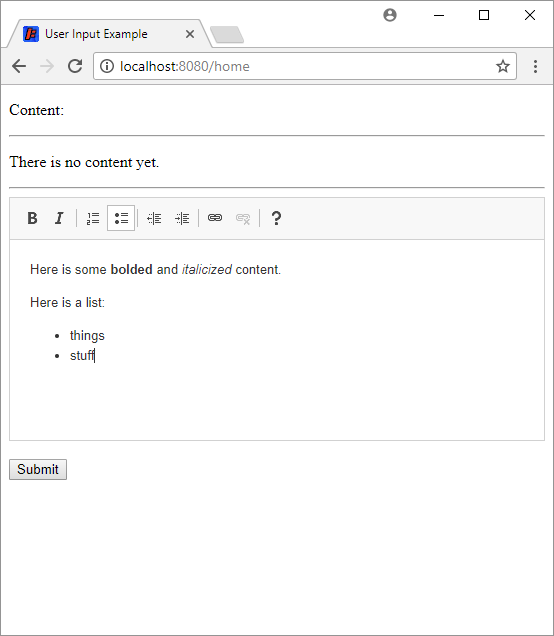
Notice that the editor now contains a toolbar that allows the user to change the formatting of the text, which is rendered in the WYSIWYG editor.
When the form is submitted, the content comes through as regular HTML text, which we can treat exactly how we’ve been treating HTML text in all of the above examples. For now we’re just rendering it in the page:
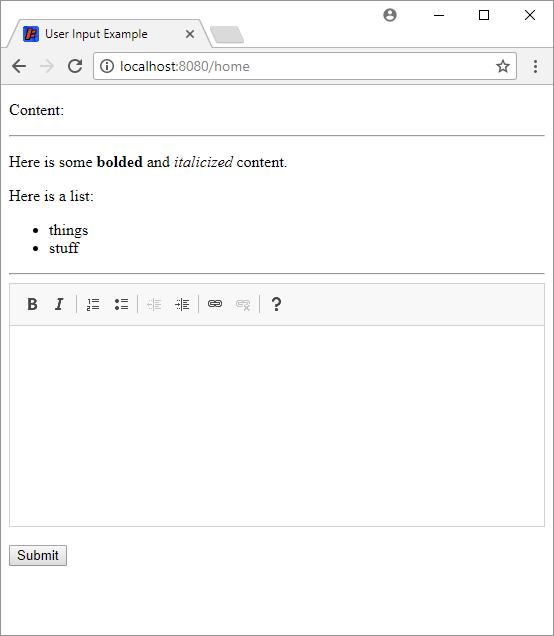
There are a ton of libraries out there for showing editors on the client and parsing content on the server, so you’ll have to find a combination that works best for you and your site.
Attributes and URLs
Keep in mind that URLs and attributes have their own content restrictions.
For example, it’s perfectly fine for HTML to contain the ? question mark character, but remember that a ? symbol in a URL represents a query string parameter. So if you’re taking user-entered usernames and constructing URLs like /users/username, what would happen if a user registered with a name of ?name=admin and you used that in your URL? The answer depends on your server code, but the point is that you need to make sure any URLs you construct are valid.
Or if you’re constructing html like <div id="username">, what would happen if a username was bad" onclick="alert('oh no!')? The user would be able to inject JavaScript into your page, which we’ve seen is very dangerous!
The point is, you have to think carefully about exactly how you’re using the content. Different types of content have different types of restrictions, and stuff that’s fine in one place might not be fine somewhere else.
We’ve pretty much already seen the solution to this problem: we need to escape content by encoding it in characters that are safe for whatever we’re using it for.
Summary
There are a bunch of ways to parse text, and there isn’t a single correct approach. What you choose depends on you and how you want your site to work, but the general process you’ll follow is:
- Decide what kind of content you want to accept.
- Decide what type of editor you want your users to interact with. Build client-side logic or find a library that creates the editor.
- Write Java code (probably using a library) that parses that input, and keep in mind that malicious users can easily get around your client-side restrictions.
- Render the parsed text back in your site.
You’‘ll probably have a combination of different types of editors and content restrictions: a username might have different content restrictions than the body of a post, which might have different content restrictions than comments.
Make sure you do a ton of testing of user input. Try breaking it with weird characters. Try breaking it by injecting HTML and JavaScript. It’s better to spend a few hours making sure everything works now than spending however much time it takes you to fix the damage after it’s done.
Homework
-
Try entering HTML in some websites that you use. What restrictions do they have? Do they have different restrictions for different types of content? For example, do usernames and comments have the same restrictions?
-
Many sites (GitHub, Twitter, Facebook, and Google to name a few) offer rewards if you find XSS vulnerabilities. Google “xss vulnerabilities reward” if this sounds interesting to you!
-
My personal favorite input method is Markdown. Find a JavaScript library that shows a Markdown preview, and find a Java library that parses the content on the server!
-
Find an editor that you like, and add it to your site. Make sure you enforce content restrictions on the server!
