How many visitors does Happy Coding get?
I have some thoughts that I want to get out, but first let me answer the question.
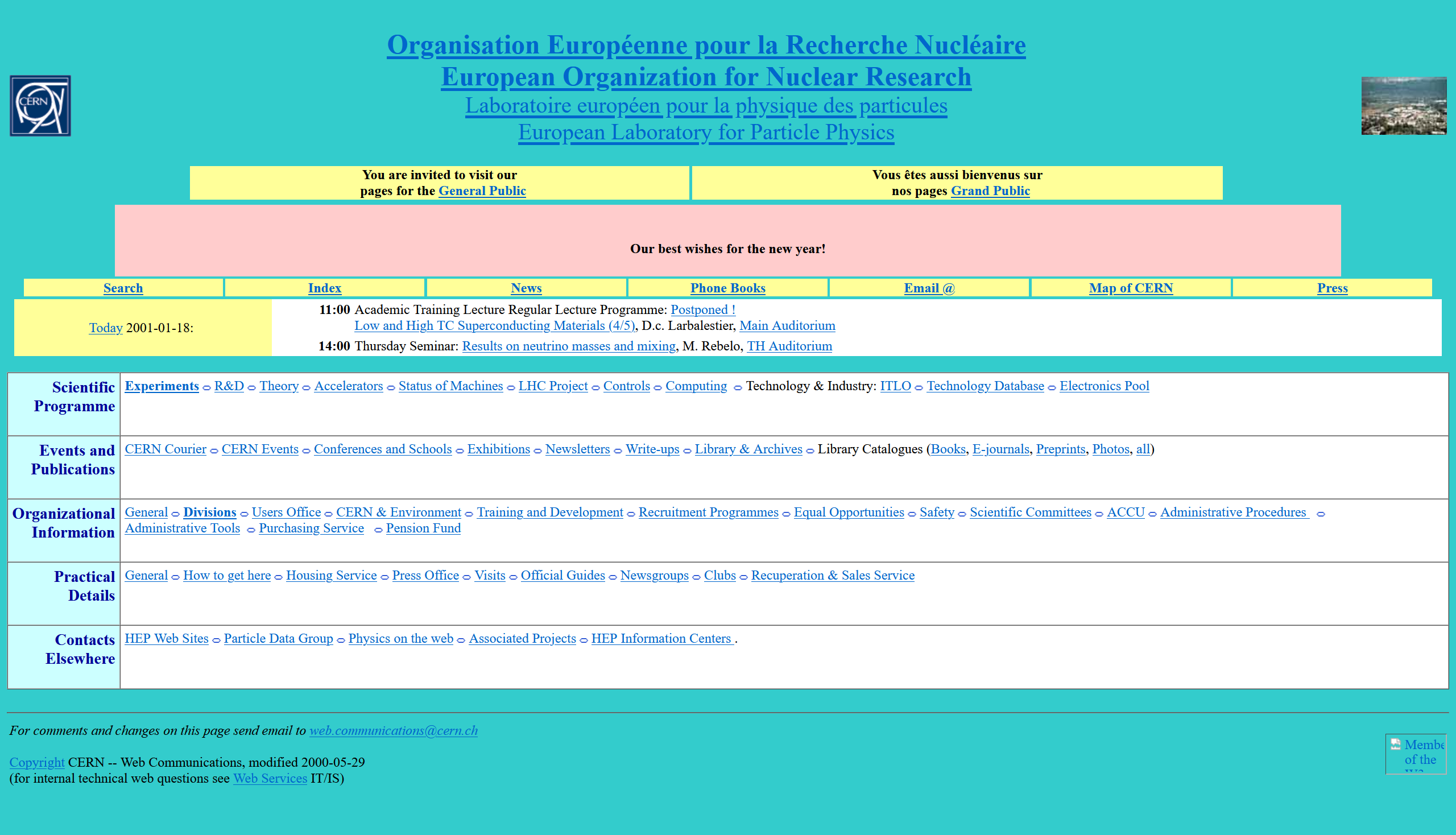
Happy Coding has had Google Analytics since pretty much the beginning. I almost never looked at it- maybe once or twice per year. But I can use it to see how many people have clicked through Happy Coding over the years:
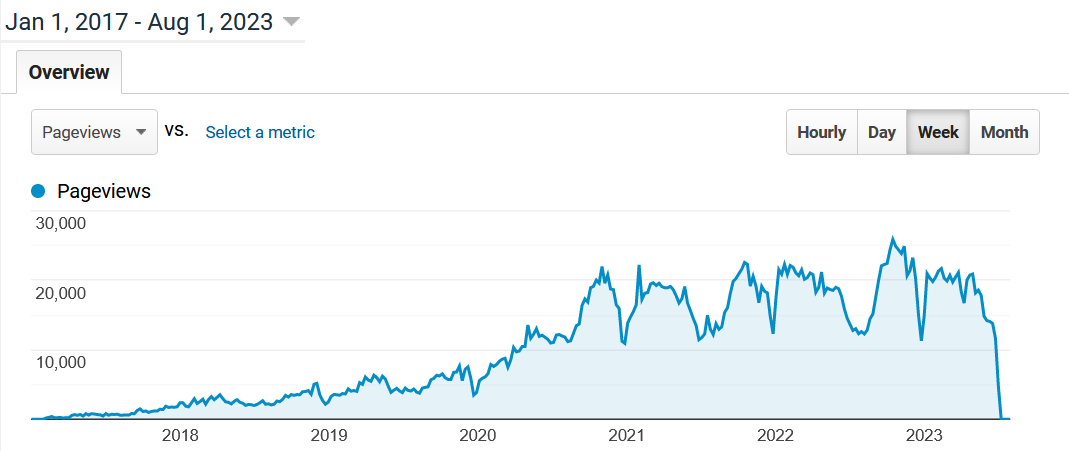
I started Happy Coding in June of 2016, and I added Google Analytics in February of 2017. This data starts then and goes through August 2023 when old versions of Google Analytics were deprecated. The page views started low and grew over time. Starting around 2020, you can see school schedules in the chart: each year starts low over winter break, then peaks during the spring semester, valleys through summer, peaks again for fall semester, and then bottoms out during winter break again.
The numbers aren’t “high” by big tech standards, but I’m happy with them. From 2020 - 2023, Happy Coding received between 10,000 and 20,000 views per week, roughly 2,500 per day or about 1,000,000 per year.
Over the past year, these numbers have dipped a little bit:
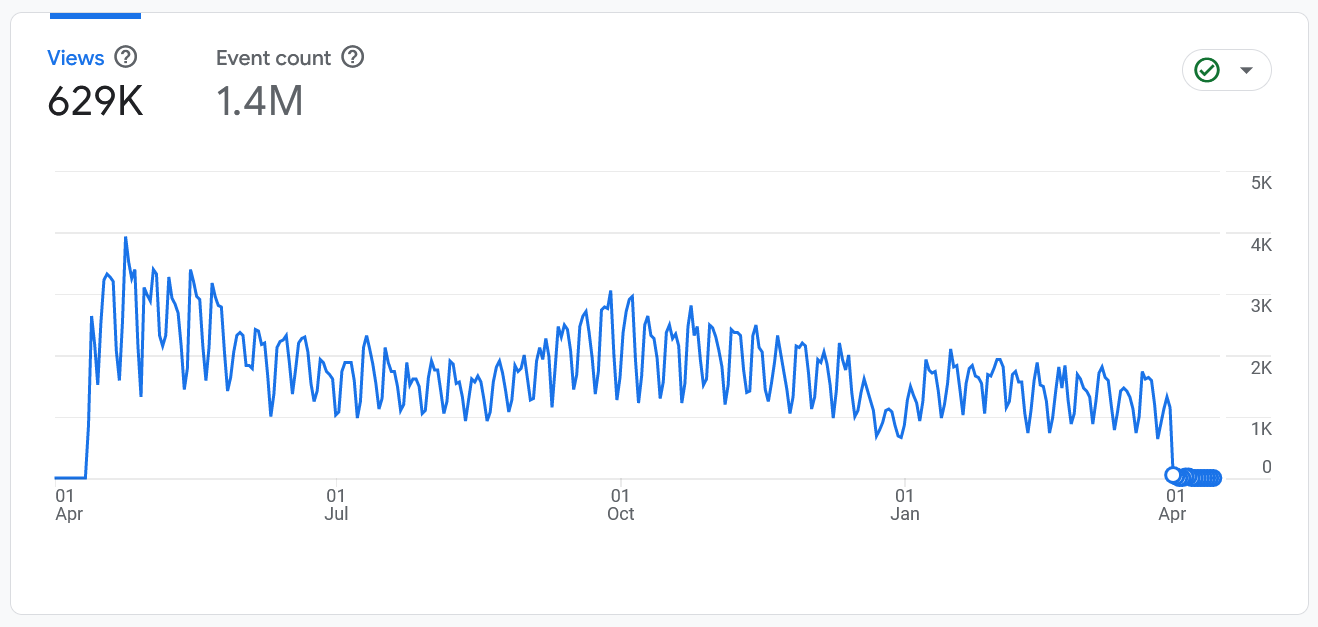
This chart shows a year of daily page views. Each peak is a week, and each valley is a weekend.
I think the downward trend makes sense, as I’ve posted less over the past year than in previous years. Then again, these numbers were collected by the new version of Google Analytics, which measures things slightly differently, so it’s hard to ascribe a ton of meaning to them. But that gives you a rough estimate of how many visitors come to Happy Coding.
Motivation
I started this post with a question: how many visitors does Happy Coding get?
This is the number one question people ask when they find out that I run a little coding tutorial website in my spare time, but I always fumble coming up with an answer.
I know they mean well, but it always feels a little like I showed them the collection of paintings I’ve created in my spare time, and they’re asking how many I’ve sold. That’s not really the point, but that’s hard to explain in a world where every website and app plays every shady trick they can come up with to compete for every last second of your attention. If you have a website, you must care about how many page views you get, right?
But I just… never really cared about making graphs go up. In the same way that some people make art just for the sake of making art, without any real plans to become rich and famous from it, I have a history of creating little programs and putting them out into the world. I also love the process of learning something and then reformulating it into tutorials or guides that other people can use. Whether people actually use them or not is almost secondary to the actual process for me.
Now of course, that’s not quite true. If it were, I would just save my ramblings to a local text file and never post it anywhere. I do love interacting with other humans who learning and creating, and I love the idea of being able to help them carve a path based on my own stumbling journey. But that’s not the same as obsessing over SEO and making graphs go up.
The Fault in Our Defaults
So why did I even have Google Analytics in the first place? Even though I never really looked at it, there’s an assumption built into web development: of course every website needs Google Analytics to track its users!
This is rolled up into a lot of issues that I’m probably going to think about over the next couple blog posts, but it comes down to big tech companies like Google becoming the default, which gives them a ridiculous amount of power over the internet, and over the world as a whole.
Here’s an example. Chances are, you use Google as your default search engine. Have you ever stopped to think about why?
In the early days, the answer was that Google Search was better than the alternatives. It had less spam, fewer dark patterns, and higher quality results. But is that still true today?
People don’t use Google because it’s better anymore. They use it because it’s the default. In fact, Google spends billions of dollars a year keeping it that way, paying other companies like Apple and Firefox to continue using Google as their default search engine.
In other words, Google doesn’t earn its position as the default, it buys it.
And this means they get to wield all of the power that comes with being the default gateway to the internet for billions of people, without being held accountable to those people. It means Google gets to change how the internet works, how society works, how we relate to each other- without earning any of that power.
I know how that sounds, but I’m not wearing a tinfoil hat. I’m not even saying you should stop using Google. I work for Google. But I think Google should have to work a little harder to make its users happy. Google should have to care.
All of this is true for other big tech companies too. In my personal life, I’ve tried to ween myself off the defaults of big tech. I try to shop locally or buy directly through companies instead of defaulting to Amazon. I use Mastodon instead of Twitter. I use Duck Duck Go instead of Google, and Firefox instead of Chrome. It’s not perfect. In fact, it’s almost impossible to quit big tech completely. But I think it’s important to be intentional about the defaults you use, and to make big tech earn your patronage.
I’m picking on Google Search because everyone knows what that is, but the same thing is true of many services put out by big tech companies. And just like Google Search is the default search engine, Google Analytics is the default way website owners measure their visitors.
This is one of the many ways Google tracks people across websites. Website owners get free tracking, and Google gets to build up profiles for anyone who visits pretty much any website, even if they didn’t go through Google to get there. But did Google earn any of that?
With all of that in mind, coupled with the fact that I barely use Google Analytics, I’ve had a goal of replacing it with an alternative for a while now.
Plausible
After a little searching and a lot of procrastination, I found Plausible.
Plausible is a minimal, open-source, privacy-driven analytics tool. Their UI is much easier than Google Analytics, and they seem to care about user privacy.
The big “downside” is that Plausible isn’t free. It’s $19 a month, which makes it by far the most expensive line item in Happy Coding’s budget. But what convinced me to try them was this blurb on the page explaining their open-source model:
We released our code on GitHub and made it easy to self-host on principle, not because it’s good business. While Plausible Community Edition can be self-hosted for free, we also sell a hosted, plug and play solution as a SaaS. This is our only source of funding. We’re growing a sustainable open source project funded solely by the fees that our subscribers pay us.
Our business model has nothing to do with collecting and analyzing huge amounts of personal information from your visitors and using these behavioral insights to sell advertisements. We don’t make money by selling or sharing your data, or abusing your visitor’s privacy.
We are not interested in raising funds or taking investment either. Plausible is completely independent and bootstrapped. Revenue from paid subscriptions is used to pay our rent, further develop Plausible and allow us to commit to open source full time.
I know these are just words, but they’re such a relief to hear. This is how technology should work. So just like I’m willing to pay a little extra to get something from a local store instead of Amazon, I’m willing to pay for Plausible, at least for now.
Anyway, setting up Plausible was super simple. It’s a single line of code:
<script defer data-domain="happycoding.io" src="https://plausible.io/js/script.outbound-links.js"></script>
And that gives me a count of visitors over time:
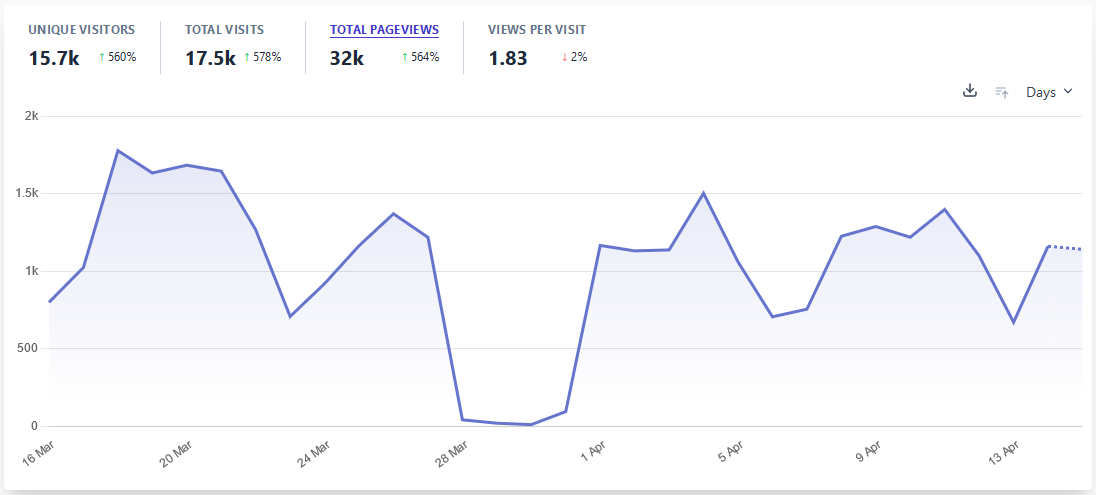
(That dip in the middle was because I managed to accidentally break something in that single line of code, and it took me a couple days to catch it.)
I kept both Google Analytics and Plausible running for about a week, long enough to confirm that the numbers were lining up. But as of now, Happy Coding officially no longer uses Google Analytics, and only uses Plausible.
New Font Who Dis
While I was at it, I also took stock of other Google services I’m using.
I host videos on YouTube. But I already use youtube-nocookie (aka privacy-enhanced mode) for all of the embedded videos, which means that viewing a video on Happy Coding is not tracked by YouTube. Switching away from YouTube entirely feels like a much bigger job, which is exactly how they want me to feel, but I only have so many hours in my day.
One tiny thing kept bothering me: I also used Google Fonts to find and host the font used by most of the text on Happy Coding. In the grand scheme of big tech, Google Fonts is pretty innocent. But it’s the same nagging question: did they earn their status as the default?
So I decided to find a new font. I clicked around some websites, opened my developer tools to see what fonts they were using, and found one I liked called Open Sans. Cool, let’s switch to that!
I tried searching for a place to download the font, and I discovered that the font was created by Google. Because of course it was.
(Technically it was created by a designer named Steve Matteson, but he was commissioned to create it for Google.)
At this point, I was pretty far down the “should I even care about this” rabbit hole, but I had to laugh. I decided to download my own copy of the font so I’m at least not sending traffic to Google Fonts anymore. But hey, Happy Coding now has a new font, so that’s cool.
What’s Next?
Part of me wishes this blog post was me swearing off big tech forever, and announcing that Happy Coding is going completely free-range, organic, open-source little tech from now on. But that’s just not feasible, at least not without spending an even more unreasonable amount of time on this little tutorial website.
Happy Coding still relies on plenty of big tech. Heck, the whole thing is hosted on GitHub Pages, which is owned by Microsoft. This site, and I, and all of us, exist within the late-stage capitalist dystopia brought on by big tech, and another coding tutorial website isn’t going to change that. And maybe that’s okay.
I’m going to keep paying for Plausible for now, but I’m not sure what my long-term plan is. If I don’t care about analytics, why have any at all?
Alternatively, maybe paying for it will force me to care about it a little more. I will never resort to using dark patterns or SEO tricks, but even I have to admit there’s some value in thinking about what I want the site to communicate to users.
For me, it’s not about getting more users. My life wouldn’t change if the numbers in these graphs doubled, or even grew by an order of magnitude. But my life would change if more of the people who visited the site said hi in the forum, or asked and answered questions, or chose to follow along with a class I was teaching, or used Happy Coding in their own classrooms.
I have some thoughts in that direction, but for now I’m going to celebrate making big tech work just a little harder to be the default.
]]>