System Design

































System Design
So far, you’ve learned about behavioral interviews where you talk about yourself, and you’ve learned about technical interviews where you work through coding problems. If you’re interviewing for a software engineering role, you might encounter another type of interview: a system design interview.
System design is the process of creating a high-level end-to-end plan for an entire product or feature. It might involve a little coding, but it’s not as focused on the details like a Leetcode problem would be. Instead, system design interviews test your ability to break down a large project into individual steps, and your knowledge of how different technologies interact.
We’ve talked about driving the conversation during technical interviews, and that becomes even more important in system design interviews!
Growing Pains
System design questions are often framed around what I think of as the ever-growing problem where the interviewer continually introduces more scale to the question. A system design conversation might go something like this:
Interviewer: How would you represent the data for a social media site?
Candidate: I might create a
Userclass, and a user can follow other users, so maybe theUserclass contains aListof otherUserinstances to represent following. Then I might create aPostclass which could contain text and images, and a timestamp. TheUserclass could also contain aListofPostinstances. Then to create somebody’s feed, I could sort the posts of every user they follow and show the most recent posts.Interviewer: What if you had so many users and posts that they wouldn’t fit in memory?
Candidate: In that case, I would store the users and posts in a database. Instead of storing everything in in-memory lists, I would implement logic that queried that database to return the data I needed to fulfill a single request.
Interviewer: what if you had so many users and posts that they wouldn’t fit onto a single hard drive?
Candidate: That means I’d have to shard my database. I might start by sharding by username, so users with usernames that start with A would be in one database, and users with usernames that start with B would be in another, etc. I could do the same thing for posts. If I did that, I’d need another layer of logic that routed queries for a particular username to the correct database shard.
Your interviewer will always have a follow-up question that complicates your initial design. This might sound frustrating, but the rest of this tutorial talks about strategies you can use to drive the conversation.
Requirements
Similar to how we’ve talked about how important it is to ask questions during technical interviews, the most important part of a system design interview is to establish the requirements of the problem.
Try to drive the conversation and offer your own ideas instead of asking questions. Consider the difference between these two conversations:
Interviewer: How would you design a pizza delivery service?
Candidate: What are the requirements for this pizza delivery service?
Interviewer: How would you design a pizza delivery service?
Candidate: First, I’d start out by defining a set of requirements. Obviously, the most important functionality would be to allow users to order pizzas. Users should be able to provide their addresses, as well as their orders. Orders would include a size like small, medium, or large, as well as a list of toppings like pineapples, onions, and green peppers. Our service would also need to route these orders to kitchens and drivers. Can you think of anything I’m missing?
This is a bit contrived, but hopefully it shows the difference between asking for requirements and coming up with requirements.
Also notice that this phase of the conversation does not include any technical details. The goal is to establish requirements, not to dive immediately into the implementation or even the representation. Make sure you understand all of the requirements before you start designing your system!
MVC
Design patterns represent different ways of breaking down a system into related parts.
To be honest, I have mixed feelings about design patterns: I think it is important to understand that you can approach every problem in a number of different ways, but I also think that “thinking in design patterns” tends to be too prescriptive in the real world.
That being said, I personally experienced an “ah-ha” moment when I finally mapped the MVC (model-view-controller) design pattern to my understanding of how real-world projects are organized. In college, MVC was mostly a theory, but I didn’t “get it” until I had worked in quite a few systems myself.
MVC breaks the system down into three pieces:
- Model: The underlying representation of the data.
- View: The user interface that allows interaction between the user and the data.
- Controller: The “logical” layer between the model and the view, which converts user actions in the view into interactions with the model.
I learned about MVC in college, and I remember not really understanding the point of the whole thing. Fast forward a few years, after I had worked on a few systems in the real world, and I finally understood the goal of the MVC design pattern.
I realized that it makes more sense to me if I think about it as the MCV design pattern:
- Model: The database. This is the underlying data schema.
- Controller: The server. This is the set of endpoints that provide access to the database and business logic.
- View: The UI, or user interface. This is the product that a human uses to interact with the system.
In this understanding, the user interacts with the view to accomplish some goal. The view then interacts with the controller to translate that user goal to a technical process or request. The controller then interacts with the model to modify or request specific data. Finally, the view renders the data from the model so the user can take their next action.
MVC (or MCV) isn’t the only design pattern out there, but I have found it especially useful to think about system design interviews in terms of MVC.
Database
After you’ve established the requirements of your system, start thinking about how you’d store your data. This is probably a database with a table for each object you need to store.
You don’t need to draw out a full diagram, but list out the tables you’d need, and the fields they’d contain.
Sharding
After you describe your database, a common follow-up question asks what you’d do if your database contained too much data to hold on a single hard drive. The general answer to this is to shard your database so that data is stored on multiple machines.
You can vertically shard your database by splitting your data into separate tables, and storing each table in its own database. In the pizza delivery example, you might have a Customer table and an Order table. You could also split your tables further: for example, you could store addresses directly in the Customer table, or you could split that data into its own Address table.
Alternatively, you can horizontally shard your database by splitting your data into rows, and storing different rows in particular databases. For example, you might store customers with names starting with A in one database, with B in another, and so on.
You can also geographically shard your data by storing data for particular regions in their own databases. This has the benefit of being able to physically locate your databases and servers closer to the users who will request that data.
No matter what your sharding approach, you’ll then need another layer that takes a request and routes it to the correct database shard. This doesn’t have to be very involved, but you should mention that you’ll need it.
Server
After you talk through your database design, move on to design the business logic of your system.
This will often take the form of a REST API, where a server exposes endpoints that interact with your database.
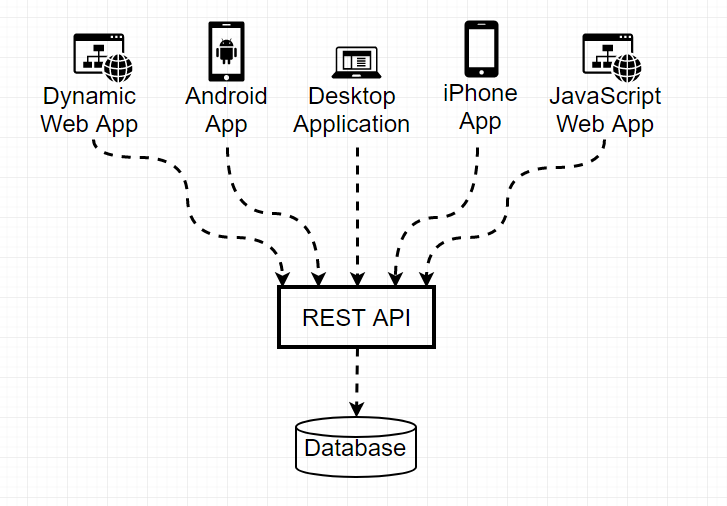
Talk about what endpoints you need, based on the ways users can interact with your data. Acronyms like CRUDL (create, read, update, delete, list) can help remind you of the typical actions you should be thinking about.
The outcome of this phase of the design discussion is likely a drawing of your services, and the endpoints in each service.
UI
Finally, now that you’ve fleshed out your database and server layers, you can talk about the user interface.
Is this a website? A mobile app? A desktop application? Does every user see the same thing, or do you need different UIs for different users?
Draw out a few mocks for the main views in your UI, and map them to the endpoints of your server. Talk about how the users interact with the UI, which interacts with the server, which interacts with the database.
Your mocks don’t have to be perfect! The goal is to communicate your overall design. You can always come back and talk about specific implementation details later.
Load Balancing
Similar to database sharding, you can use load balancing to handle requests (either to your server, or to your UI if it’s web-based) that become too complicated for a single computer.
In other words, if your system needs to scale to handle many requests, you might add multiple servers that all talk to the same database. Then you’d add another layer (the load balancer) that routes requests to the least-busy server.
Failing Gracefully
As you’re talking through your requirements and your system design, think about your failure modes. What functionality in your system is essential? What could you disable if you needed to?
For example, let’s say my pizza delivery system contains a service that autocompletes addresses, so new users can more easily enter their delivery addresses. That feature is nice to have, but if suddenly the whole system receives a ton of traffic, it might make sense to disable the address autocomplete feature to free up resources for more important services, like ordering pizzas.
Real Tech Stacks
The majority of a system design interview is about talking through a high-level approach to solving a large problem, like creating an entire product or feature. The conversation stays pretty general.
However, if you’re familiar with specific tech stacks, you can volunteer specific solutions to the above problems. If you know about a tool that helps with database sharding, then you should absolutely bring that up. Bonus points if the tech stack is what the company actually uses! (Which you can figure out by asking questions earlier in the interview process.)
You might use a stack like LAMP, or MEAN, or LYME. If you don’t know what those are, that’s okay! Focus on the parts of the stack that you do know- what would you actually use if your job was to implement the overall feature?
From System Design to Code
System design interviews are more about communicating an overall plan, and the “deliverable” is probably a series of diagrams that help you explain how the different pieces of your system fit together.
But you should be prepared to drill down into any part of the system, and write some code that accomplishes a specific task. For example, you might be asked to implement an example load balancer, or you might be asked to write the code for your UI.
You can help yourself by designing your system in ways that you’d be able to implement. You can also tell your interviewer which pieces you’d like to spend more time on, to highlight the parts of the stack that you’re more familiar with.
Summary
System design interviews can seem scary, because they require talking about pretty much every part of software engineering. But it’s impossible to be an expert in everything.
The good news is, you don’t have to be an expert in everything! System design interviews start at a very high level, and you can “hand wave” your way through a lot of it. You don’t need to be an expert in database sharding or load balancing or API implementation or UI design. But you do have to know that each of those pieces exist, and how they fit together.
The overall goal of a system design interview is to communicate the fact that you understand how a large system works together, and the tradeoffs that you might make at each level.
Learn More
- Shard - Wikipedia
- Understanding Database Sharding - Digital Ocean
- Creating a REST API - Happy Coding
- Architectural patterns - Wikipedia
- Design patterns - Wikipedia
- Creating a Social App - Happy Coding is a bit tongue-in-cheek, but it talks through the main pieces you’d include in a system design interview.